
Productgegevens vormen de hoeksteen van succes, van het begrijpen van klantvoorkeuren tot het optimaliseren van voorraadniveaus, het effectieve gebruik van productgegevens kan belangrijke bedrijfsresultaten opleveren. Om het volledige potentieel van productgegevens te ontsluiten, moeten organisaties dus een gestructureerde aanpak volgen die bekend staat als de Data Hierarchy of Needs. Dit raamwerk schetst de essentiële stadia van het gebruik van productgegevens en begeleidt organisaties van de basiselementen tot geavanceerde kunstmatige intelligentie (AI)-toepassingen. In dit artikel beginnen we aan een reis door de hiërarchie van behoeften op het gebied van gegevens, met een specifieke focus op productgegevens, waarbij we het belang en de implicaties voor bedrijven ontrafelen.
*Zie de afbeelding van de piramide hieronder als we beginnen aan een reis door de Data Hierarchy of Needs, waarbij we van de basisstadia onderaan naar het toppunt van geavanceerde AI-toepassingen bovenaan gaan.
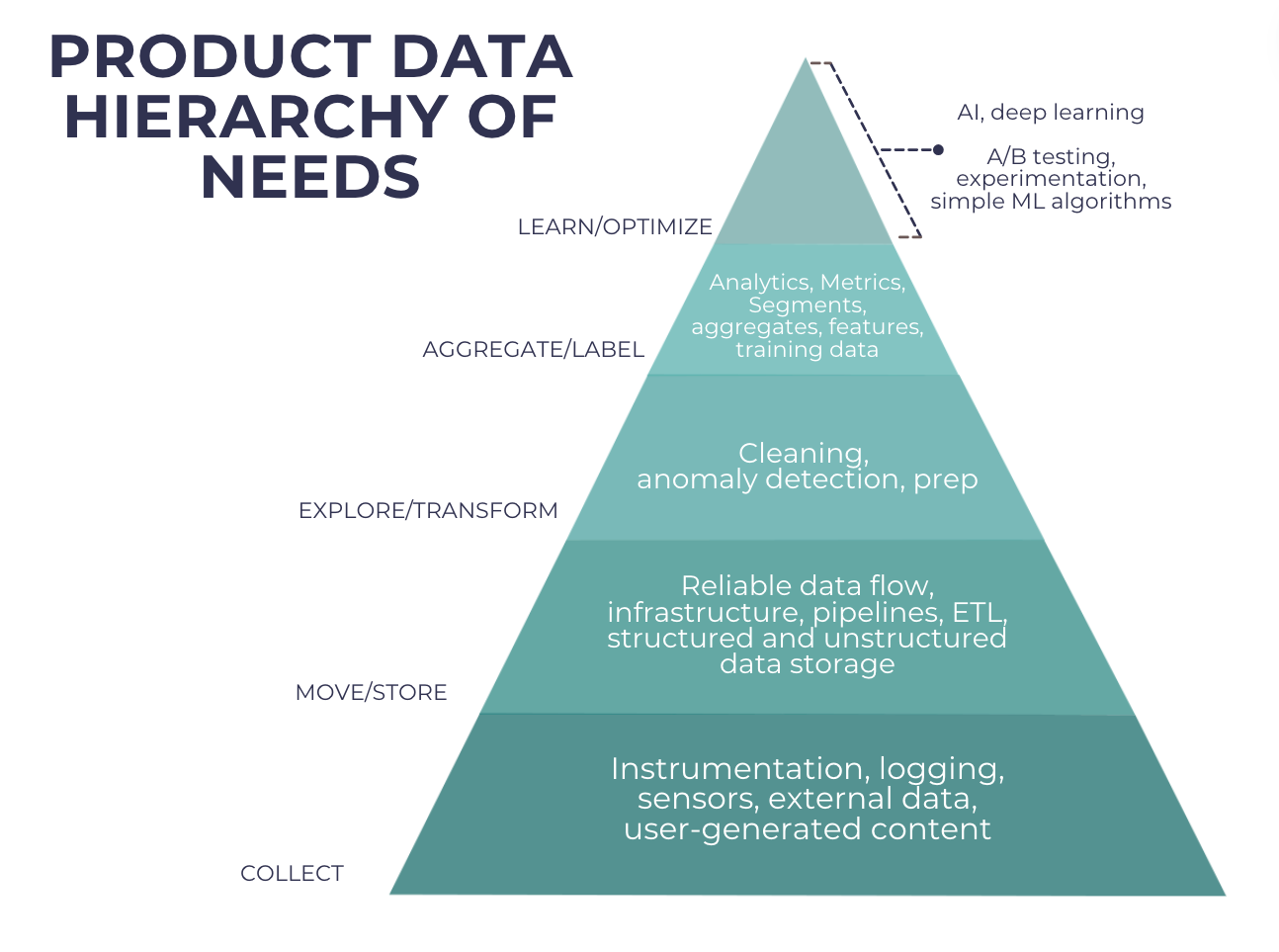
Verzamelen: Fundamentele pijlers van productgegevens
Aan de basis van de gegevenshiërarchie van behoeften staat de fase ‘Verzamelen’, die de basispijlers van het verzamelen van productgegevens vertegenwoordigt:
– Instrumentatie: Traceermechanismen implementeren om productinteracties, gebruikersgedrag en verkoopgegevens vast te leggen op digitale platforms.
– Vastleggen: Vastleggen van productgerelateerde activiteiten, zoals klikken, bekijken en aankopen, om inzicht te krijgen in de voorkeuren en kooppatronen van klanten.
– Externe gegevens: Externe bronnen zoals markttrends, concurrentieanalyses en brancherapporten integreren om productdatasets te verrijken.
– Door gebruikers gegenereerde inhoud: Het verzamelen van feedback, beoordelingen en waarderingen van gebruikers om de stemming en tevredenheid over het product te meten.
Voorbeeld: Een e-commerce platform verzamelt gegevens over productweergaven, add-to-cart acties en aankooptransacties om productprestaties te analyseren en marketingcampagnes te optimaliseren.
Verhuizen/Store: Een robuuste infrastructuur bouwen
Hoger in de hiërarchie richten organisaties zich op het opzetten van een robuuste infrastructuur voor de opslag en het beheer van productgegevens:
– Betrouwbare gegevensstroom: zorgen voor naadloze gegevensoverdracht tussen systemen, databases en applicaties om de integriteit en toegankelijkheid van gegevens te behouden.
– Infrastructuur: Het inzetten van schaalbare en veilige opslagoplossingen, zoals datawarehouses of cloudplatforms, om groeiende hoeveelheden productgegevens te kunnen verwerken.
– Pijplijnen: Het ontwerpen van geautomatiseerde datapijplijnen voor het efficiënt verwerken, transformeren en laden van gegevens in opslagplaatsen.
– ETL-processen: Extract-, Transform- en Load-processen implementeren om gegevens te standaardiseren, op te schonen en te organiseren voor analyse en rapportage.
Voorbeeld: Een winkelketen gebruikt cloud-gebaseerde opslagoplossingen en datapijplijnen om productgegevens van verschillende winkels samen te voegen, waardoor gecentraliseerd voorraadbeheer en vraagvoorspelling mogelijk worden.
Verkennen/Transformeren: Productinzichten verfijnen
Verder in de hiërarchie richten organisaties zich op het verfijnen van ruwe gegevens tot bruikbare inzichten:
– Gegevens opschonen: Identificeren en corrigeren van inconsistenties, fouten en duplicaten binnen productdatasets om nauwkeurigheid en betrouwbaarheid te garanderen.
– Anomaliedetectie: Het detecteren van onregelmatige patronen of uitschieters in gegevens die kunnen duiden op anomalieën of opkomende trends die aandacht vereisen.
– Voorbereiding: Gegevens voorbereiden voor analyse door het structureren, normaliseren en verrijken van datasets met relevante attributen en metadata.
Voorbeeld: Een softwarebedrijf zuivert en transformeert gegevens over productgebruik om de mate van gebruik van functies, patronen in gebruikersbetrokkenheid en potentiële gebieden voor productverbetering te identificeren.
Samenvoegen/Label: Afleiden van bruikbare informatie
In het tussenstadium van de hiërarchie richten organisaties zich op het samenvoegen en labelen van gegevens om er bruikbare informatie uit af te leiden:
– Analytics: Statistische methoden, datavisualisatietechnieken en voorspellende modellen toepassen om productprestaties, klantgedrag en markttrends te analyseren.
– Metriek: Het definiëren van belangrijke prestatie-indicatoren (KPI’s) en prestatiebenchmarks om de effectiviteit van productstrategieën en -initiatieven te evalueren.
– Segmenten/aggregaten/kenmerken: Gegevens segmenteren op basis van klantdemografie, geografische regio’s of aankoopgeschiedenis om marketingcampagnes en productaanbevelingen te personaliseren.
Voorbeeld: Een online marktplaats verzamelt verkoopgegevens van producten om best verkopende categorieën, waardevolle klanten en opkomende markttrends te identificeren, zodat voorraadbeheer en prijsstrategieën kunnen worden bepaald.
Leren/optimaliseren: AI omarmen voor productinnovatie
Op het toppunt van de Data Hierarchy of Needs ligt de ‘Learn/Optimize’-fase, waarin organisaties geavanceerde AI-technologieën inzetten om productinnovatie te stimuleren:
– A/B-testen: Het uitvoeren van gecontroleerde experimenten om productvariaties te vergelijken en de gebruikerservaring, prijsstrategieën en implementaties van functies te optimaliseren.
– Experimenteren: Iteratief testen van hypotheses en verfijnen van producteigenschappen op basis van feedback van gebruikers, marktdynamiek en concurrentieanalyse.
– Eenvoudige ML-algoritmen: Machine learning-algoritmen inzetten voor productaanbevelingen, vraagvoorspelling en klantsegmentatie om personalisatie en gebruikersbetrokkenheid te verbeteren.
– AI, diep leren: Gebruikmaken van geavanceerde AI- en deep learning-technieken voor beeldherkenning, natuurlijke taalverwerking en sentimentanalyse om diepere inzichten te halen uit productgegevens.
Voorbeeld: Een e-commerceplatform maakt gebruik van AI-aanbevelingsengines om gepersonaliseerde productsuggesties te doen op basis van de browsegeschiedenis, het aankoopgedrag en de voorkeuren van de gebruiker, waardoor de algehele winkelervaring wordt verbeterd en de conversie wordt verhoogd.
Het navigeren door de hiërarchie van gegevensbehoeften is essentieel voor organisaties die het volledige potentieel van productgegevens willen benutten. Door de fasen van Verzamelen tot Leren/Optimaliseren te doorlopen, kunnen bedrijven de kracht van gegevens gebruiken om productinnovatie te stimuleren, klantervaringen te verbeteren en een concurrentievoordeel te behalen op de dynamische markt. Met AI in de voorhoede van data-analyse kunnen organisaties nieuwe mogelijkheden verkennen, waarbij ruwe gegevens worden omgezet in bruikbare intelligentie en groei en innovatie in het digitale tijdperk worden gestimuleerd.
Vragen? Plan een gratis gesprek met een PIM specialist
Ontdek hoe we u kunnen helpen met elk vraagstuk op het gebied van Product Information Management.
Plan een gratis gesprek