
Product data serves as the cornerstone of success, from understanding customer preferences to optimizing inventory levels, the effective utilization of product data can drive significant business outcomes. Thus, to unlock the full potential of product data, organizations must adhere to a structured approach known as the Data Hierarchy of Needs. This framework delineates the essential stages of product data utilization, guiding organizations from the foundational elements to advanced artificial intelligence (AI) applications. In this article, we embark on a journey through the Data Hierarchy of Needs, with a specific focus on product data, unraveling its significance and implications for businesses.
*Please see the image of the pyramid below as we embark on a journey through the Data Hierarchy of Needs, progressing from the foundational stages at the bottom to the pinnacle of advanced AI applications at the top.
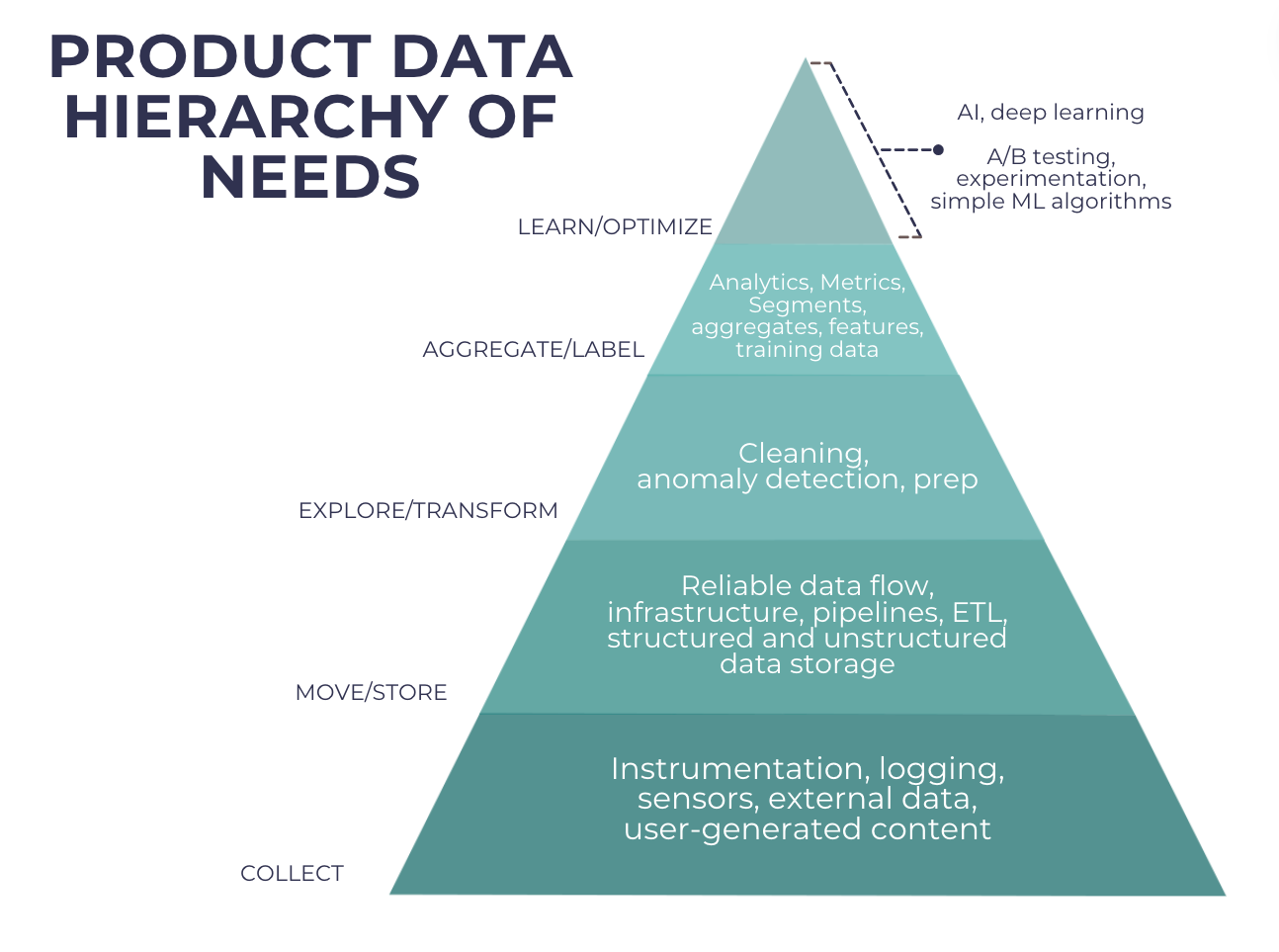
Collect: Foundational Pillars of Product Data
At the base of the Data Hierarchy of Needs lies the ‘Collect’ stage, representing the foundational pillars of product data acquisition:
– Instrumentation: Implementing tracking mechanisms to capture product interactions, user behavior, and sales data across digital platforms.
– Logging: Recording product-related activities, including clicks, views, and purchases, to gain insights into customer preferences and buying patterns.
– External Data: Integrating external sources such as market trends, competitor analysis, and industry reports to enrich product datasets.
– User-Generated Content: Collecting feedback, reviews, and ratings provided by users to gauge product sentiment and satisfaction levels.
Example: An e-commerce platform collects data on product views, add-to-cart actions, and purchase transactions to analyze product performance and optimize marketing campaigns.
Move/Store: Building a Robust Infrastructure
Moving up the hierarchy, organizations focus on establishing a robust infrastructure for the storage and management of product data:
– Reliable Data Flow: Ensuring seamless data transfer between systems, databases, and applications to maintain data integrity and accessibility.
– Infrastructure: Deploying scalable and secure storage solutions, such as data warehouses or cloud platforms, to accommodate growing volumes of product data.
– Pipelines: Designing automated data pipelines for the efficient processing, transformation, and loading of data into storage repositories.
– ETL Processes: Implementing Extract, Transform, and Load processes to standardize, clean, and organize data for analysis and reporting.
Example: A retail chain utilizes cloud-based storage solutions and data pipelines to aggregate product data from various stores, enabling centralized inventory management and demand forecasting.
Explore/Transform: Refining Product Insights
Moving further along the hierarchy, organizations focus on refining raw data into actionable insights:
– Data Cleaning: Identifying and rectifying inconsistencies, errors, and duplicates within product datasets to ensure accuracy and reliability.
– Anomaly Detection: Detecting irregular patterns or outliers in data that may signify anomalies or emerging trends requiring attention.
– Preparation: Preparing data for analysis by structuring, normalizing, and enriching datasets with relevant attributes and metadata.
Example: A software company cleans and transforms product usage data to identify feature adoption rates, user engagement patterns, and potential areas for product improvement.
Aggregate/Label: Deriving Actionable Intelligence
At the intermediate stage of the hierarchy, organizations focus on aggregating and labeling data to derive actionable intelligence:
– Analytics: Applying statistical methods, data visualization techniques, and predictive models to analyze product performance, customer behavior, and market trends.
– Metrics: Defining key performance indicators (KPIs) and performance benchmarks to evaluate the effectiveness of product strategies and initiatives.
– Segments/Aggregates/Features: Segmenting data based on customer demographics, geographic regions, or purchase history to personalize marketing campaigns and product recommendations.
Example: An online marketplace aggregates product sales data to identify top-selling categories, high-value customers, and emerging market trends, informing inventory management and pricing strategies.
Learn/Optimize: Embracing AI for Product Innovation
At the pinnacle of the Data Hierarchy of Needs lies the ‘Learn/Optimize’ stage, where organizations leverage advanced AI technologies to drive product innovation:
– A/B Testing: Conducting controlled experiments to compare product variations and optimize user experience, pricing strategies, and feature implementations.
– Experimentation: Iteratively testing hypotheses and refining product features based on user feedback, market dynamics, and competitive analysis.
– Simple ML Algorithms: Deploying machine learning algorithms for product recommendations, demand forecasting, and customer segmentation to enhance personalization and user engagement.
– AI, Deep Learning: Harnessing advanced AI and deep learning techniques for image recognition, natural language processing, and sentiment analysis to extract deeper insights from product data.
Example: An e-commerce platform employs AI-powered recommendation engines to deliver personalized product suggestions based on user browsing history, purchase behavior, and preferences, enhancing the overall shopping experience and driving conversion rates.
Navigating the Data Hierarchy of Needs is essential for organizations seeking to unlock the full potential of product data. By progressing through the stages from Collect to Learn/Optimize, businesses can harness the power of data to drive product innovation, enhance customer experiences, and gain a competitive edge in the dynamic marketplace. With AI at the forefront of data analytics, organizations can explore new frontiers of possibility, transforming raw data into actionable intelligence and fueling growth and innovation in the digital age.
Questions? Schedule a free call with a PIM specialist
Find out how we can help you with any Product Information Management issue.
Schedule a free call
